I tried SD 9 months ago, and since then it has gotten a lot easier to set up and generate decent images.
Setup
Test Runs
SD1.5 img2img
Using A1111, I transformed my drawing from this:
to this:

SDXL
I wanted to try out SDXL models. The problem was I couldn’t run the models in A1111 locally, even if --medvram-sdxl command line arg. 6GB VRAM isn’t enough for SDXL.
I could use some paid cloud services (free ones usually have a long queue and not many supported SDXL back then), which I will do in the future.
While browsing the internet, I came across ComfyUI which was said to use less memory for SDXL than A1111. It did work, I could generate an image with SDXL models; admittedly it took a long time.
It was a big learning curve coming from GUI to node coding. I didn’t have good experience with Low Code visual programming, so I began with heavy bias. Playing with ComfyUI still didn’t convince me that drag and drop coding was better. A lot of time, I wished it was normal programming. Just a few lines of code could replace multiple nodes and connections.
I didn’t know what I was doing, and I’m still learning now. My first major attempt was to generate an image from an SDXL model, upscale latent by 2, then pass it to a SD1.5 model. In other word, the process was txt2img, latent upscale then img2img. Why did I do it? It was just to see how hard it was to set it up in ComfyUI.
It took a few days before I got something working. These are the fruit of my work:
Generated from an SDXL model:

Used an anime SD1.5 model to change the style of the first image.

Run the workflow again with different seed and a different anime SD1.5 model gave me this:

This is my messy but working workflow:
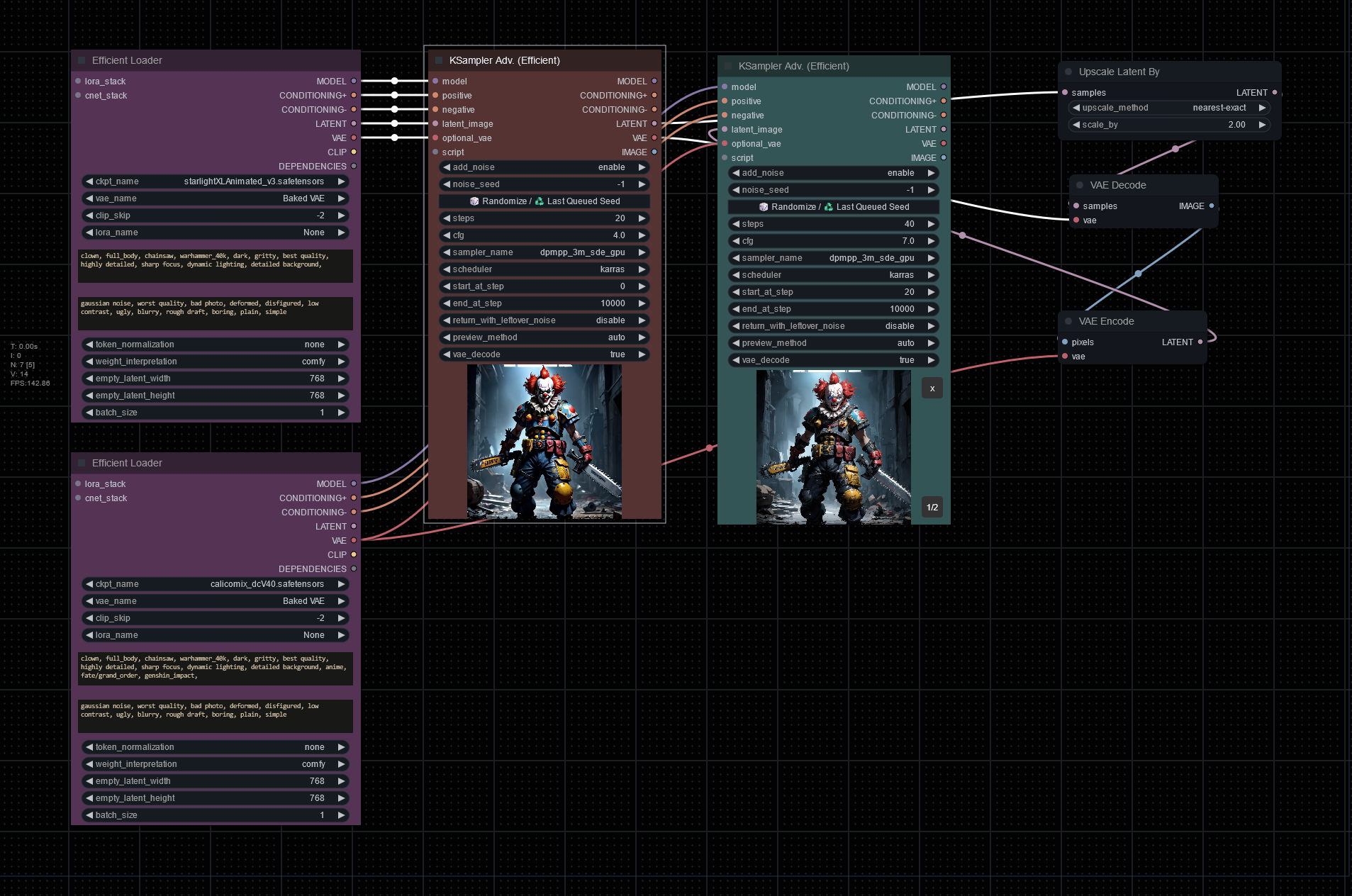
The images look interesting, but there are a lot of nonsensical details. For example, the clown doesn’t know how to hold an object. If I improve my prompts, I wonder if it could be fixed. AI doesn’t seem to be good at drawing hand at the moment.
ControlNet
Scribble
My drawing:

I used scribble model to transform it into an image:

Pose
Got a royalty free stock image and process it into a control image:
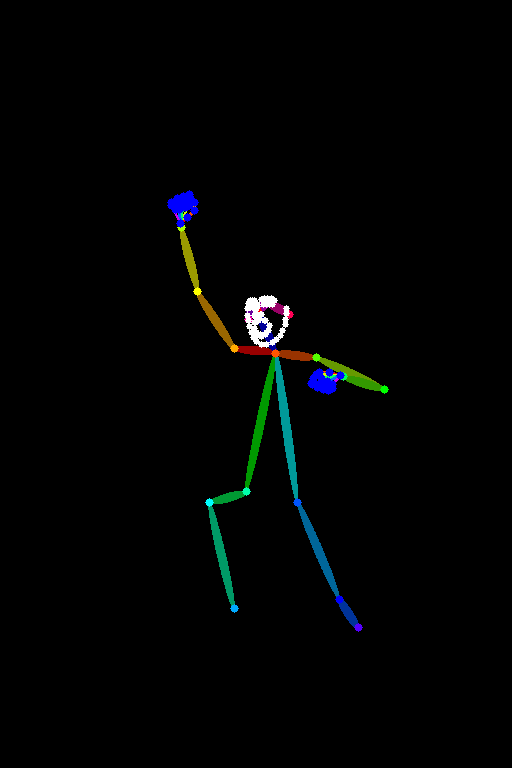
Applied the open pose model to generate a new image:

SDXL Turbo
This is faster than using regular SDXL, as it requires lower sampling steps. The generated image from SDXL Turbo has low details, so it needs to be upscaled and processed via img2img.
Generated from a SDXL Turbo model:

After upscaling the image by 2, and process it with an SD1.5 model:

I tried SD1.5 LCM and the speed is fast, but the quality is also low.
Current Workflow
- Use SDXL to create an image.
- Upscale with AI upscalers (Real-ESRGAN), then downscale them to 2x original image.
- Pass image through img2img, using SD1.5 model.
TODO
- Animation
- Learn how to fix hands in GIMP or Krita
- SDXL pony
- SD3